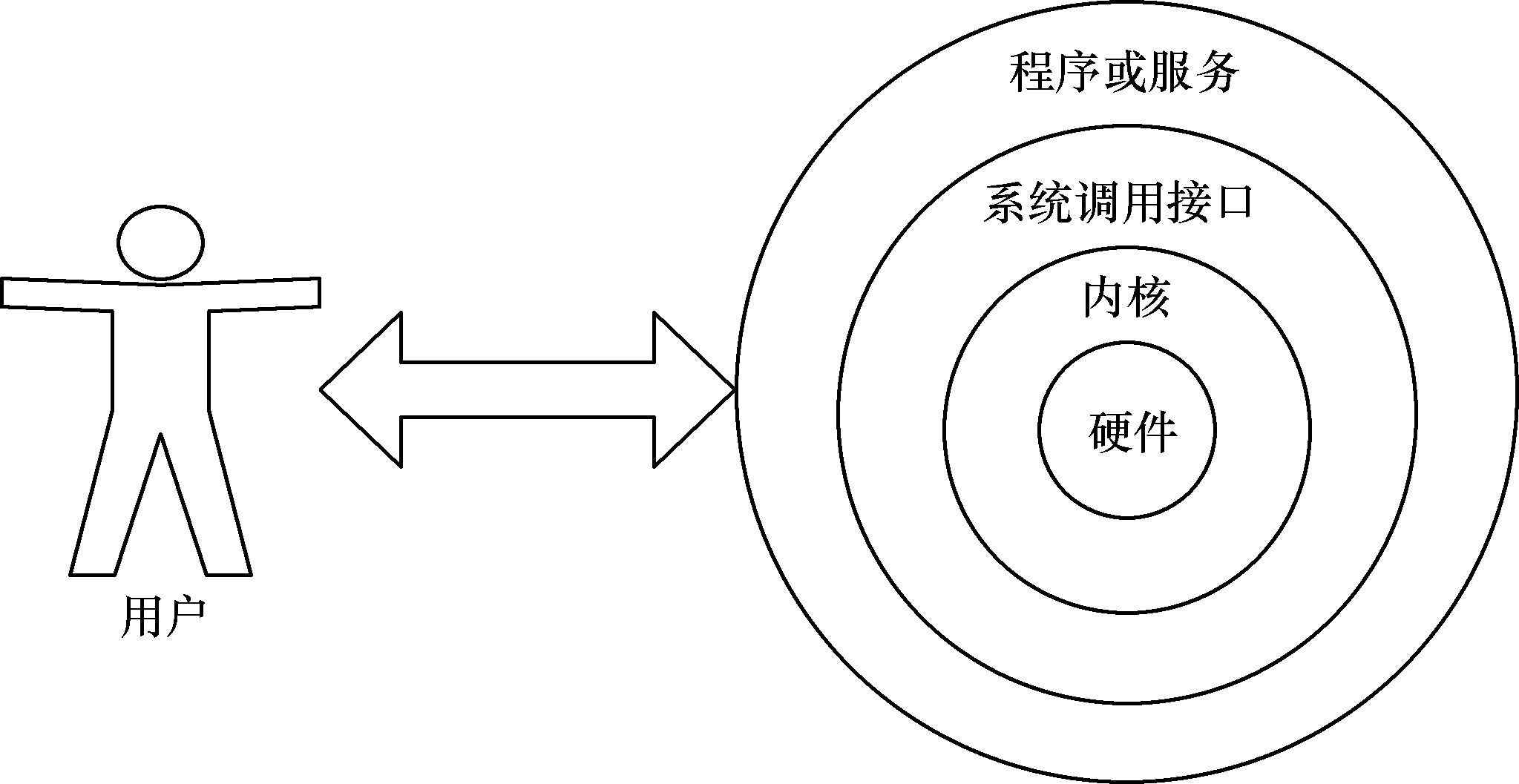
文件目录管理 grep grep命令用于在文本中执行关键词搜索,并显示匹配的结果,格式为“grep [选项] [文件]”。
参数
作用
-b
将可执行文件(binary)当作文本文件(text)来搜索
-c
仅显示找到的行数
-i
忽略大小写
-n
显示行号
-v
反向选择——仅列出没有“关键词”的行。
-A
除了显示符合范本样式的那一行之外,并显示该行之后的内容。
-B
在显示符合范本样式的那一行之外,并显示该行之前的内容。
-C
除了显示符合范本样式的那一列之外,并显示该列之前后的内容。
awk 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 localhost% cat test.txt NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME k8s01 Ready wise-controller 38d v1.16.4 192.168.0.3 <none> CentOS 3.10.0-862.el7.x86_64 docker://18.9.8 k8s02 Ready wise-controller 38d v1.16.4 192.168.0.7 <none> CentOS 3.10.0-862.el7.x86_64 docker://18.9.8 k8s03 Ready wise-controller 38d v1.16.4 192.168.0.10 <none> CentOS 3.10.0-862.el7.x86_64 docker://18.9.8 k8s04 NotReady node 38d v1.16.4 192.168.0.15 <none> CentOS 3.10.0-862.el7.x86_64 docker://18.9.8 localhost% awk '{print $1,$5}' test.txt NAME VERSION k8s01 v1.16.4 k8s02 v1.16.4 k8s03 v1.16.4 k8s04 v1.16.4 localhost% awk '{print $NF}' test.txt CONTAINER-RUNTIME docker://18.9.8 docker://18.9.8 docker://18.9.8 docker://18.9.8 localhost% awk '{print $(NF-1)}' test.txt KERNEL-VERSION 3.10.0-862.el7.x86_64 3.10.0-862.el7.x86_64 3.10.0-862.el7.x86_64 3.10.0-862.el7.x86_64 localhost% awk 'END{print NR}' test.txt 5 localhost% awk 'NR==1{print}' test.txt NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME localhost% awk 'NR>1{print}' test.txt k8s01 Ready wise-controller 38d v1.16.4 192.168.0.3 <none> CentOS 3.10.0-862.el7.x86_64 docker://18.9.8 k8s02 Ready wise-controller 38d v1.16.4 192.168.0.7 <none> CentOS 3.10.0-862.el7.x86_64 docker://18.9.8 k8s03 Ready wise-controller 38d v1.16.4 192.168.0.10 <none> CentOS 3.10.0-862.el7.x86_64 docker://18.9.8 k8s04 NotReady node 38d v1.16.4 192.168.0.15 <none> CentOS 3.10.0-862.el7.x86_64 docker://18.9.8
sed 定位到数据行并对数据进行增删改查操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 sed 's/book/books/' file [root@harbor image_pull_push]# cat img-list.txt |sed 's/registry.cn-hangzhou.aliyuncs.com/192.168.0.11/g' echo sksksksksksk | sed 's/sk/SK/3g' skskSKSKSKSK oldip=172.22.12.241 newip=172.22.12.242 find . -type f | xargs grep $oldip find . -type f | xargs sed -i "s/$oldip /$newip /" find . -type f | xargs grep $newip
find find命令用于按照指定条件来查找文件,格式为“find [查找路径] 寻找条件 操作”。
参数
作用
-name
匹配名称
-perm
匹配权限(mode为完全匹配,-mode为包含即可)
-user
匹配所有者
-group
匹配所有组
-mtime -n +n
匹配修改内容的时间(-n指n天以内,+n指n天以前)
-atime -n +n
匹配访问文件的时间(-n指n天以内,+n指n天以前)
-ctime -n +n
匹配修改文件权限的时间(-n指n天以内,+n指n天以前)
-nouser
匹配无所有者的文件
-nogroup
匹配无所有组的文件
-newer f1 !f2
匹配比文件f1新但比f2旧的文件
-type b/d/c/p/l/f
匹配文件类型(后面的字幕字母依次表示块设备、目录、字符设备、管道、链接文件、文本文件)
-size
匹配文件的大小(+50KB为查找超过50KB的文件,而-50KB为查找小于50KB的文件)
-prune
忽略某个目录
-exec …… {};
后面可跟用于进一步处理搜索结果的命令(下文会有演示)
1 2 3 4 5 6 7 8 9 10 11 find . -name README.md find /etc -name host* find / -size +1024M find . -type f -name "*" | xargs grep "140.206.111.111"
echo 1 2 3 4 5 6 7 8 9 [root@harbor ~]# echo hello > new.yaml [root@harbor ~]# cat new.yaml hello [root@harbor ~]# echo hello-test >> new.yaml [root@harbor ~]# cat new.yaml hello hello-test
dd dd命令用于按照指定大小和个数的数据块来复制文件或转换文件,格式为“dd [参数]”。
Linux系统中有一个名为/dev/zero的设备文件,这个文件不会占用系统存储空间,但却可以提供无穷无尽的数据,因此可以使用它作为dd命令的输入文件,来生成一个指定大小的文件。
参数
作用
if
输入的文件名称,如果不指定if,默认就会从stdin中读取输入。
of
输出的文件名称,如果不指定of,默认就会将stdout作为默认输出。
bs
设置每个“块”的大小
count
设置要复制“块”的个数
1 2 3 4 5 [root@master01 ~]# dd if =/dev/zero of=sun.txt bs=100M count=1 1+0 records in 1+0 records out 104857600 bytes (105 MB, 100 MiB) copied, 0.0580656 s, 1.8 GB/s
1 2 3 4 5 # 测试磁盘写入速度 [root@localhost ~]# dd if=/dev/zero of=/tmp/testfile bs=1G count=1 oflag=direct 1+0 records in 1+0 records out 1073741824 bytes (1.1 GB) copied, 7.10845 s, 151 MB/s
1 2 3 4 5 # 测试磁盘读取速度 [root@localhost ~]# dd if=/tmp/testfile of=/dev/null bs=1G count=1 iflag=direct 1+0 records in 1+0 records out 1073741824 bytes (1.1 GB) copied, 6.53009 s, 164 MB/s
tar tar命令用于对文件进行打包压缩或解压,格式为“tar [选项] [文件]”。在Linux系统中,常见的文件格式比较多,其中主要使用的是.tar或.tar.gz或.tar.bz2格式。
参数
作用
-c
创建压缩文件
-x
解开压缩文件
-t
查看压缩包内有哪些文件
-z
用Gzip压缩或解压
-j
用bzip2压缩或解压
-v
显示压缩或解压的过程
-f
目标文件名
-p
保留原始的权限与属性
-P
使用绝对路径来压缩
-C
指定解压到的目录
命令示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 tar -cvf /tmp/bin-backup.tar /home/vivek/bin/ tar -jcvf /tmp/bin-backup.tar.bz2 /home/vivek/bin/ tar -zcvf /tmp/bin-backup.tar.gz /home/vivek/bin/ tar -zxvf bin-backup.tar.gz tar -tvf /opt/extra.tgz
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 上下翻页:Ctrl+f、Ctrl+b 跳到当前行最后字符处:Fn+右键 跳到当前行最前面字符处:Fn+左键、0 查找字符串:/字符串 n继续查找 字符全局替换::%s/foo/bar/g :{作用范围}s/{目标}/{替换}/{替换标志} x或X:删除一个字符,x删除光标后的,而X删除光标前的; D:删除从当前光标到光标所在行尾的全部字符; 删除行:dd ndd(n代表删除或复制的行数) 复制行:yy nyy 粘贴行:p、P 复原前一个操作:u 重做上一个操作:ctrl+r 显示行号::set nu Ctrl+u:向文件首翻半屏; Ctrl+d:向文件尾翻半屏; Ctrl+f:向文件尾翻一屏; Ctrl+b:向文件首翻一屏; Esc:从编辑模式切换到命令模式; ZZ:命令模式下保存当前文件所做的修改后退出vi; :行号:光标跳转到指定行的行首; :$:光标跳转到最后一行的行首;
scp scp命令 用于在Linux下进行远程拷贝文件的命令,和它类似的命令有cp,不过cp只是在本机进行拷贝不能跨服务器,而且scp传输是加密的。
1 2 3 4 5 scp -r root@10.10.10.10:/opt/soft/mongodb /opt/soft/ scp -r /opt/soft/mongodb root@10.10.10.10:/opt/soft/scptest
vi vi编辑器提供了丰富的内置命令,有些内置命令使用键盘组合键即可完成,有些内置命令则需要以冒号“:”开头输入。
常用内置命令如下:
命令
作用
dd
删除(剪切)光标所在整行
5dd
删除(剪切)从光标处开始的5行
yy
复制光标所在整行
5yy
复制从光标处开始的5行
u
撤销上一步的操作
p
将之前删除(dd)或复制(yy)过的数据粘贴到光标后面
D
删除光标处所在行尾的全部字符
x
删除光标处的一个字符
:set nu
显示行号
/string、?string
查找字符串,常结合n/N可以继续查找上一个、下一个字符串
:s/foo/bar/g
将当前光标所在行的所有foo替换成bar
:%s/foo/bar/g
将全文中的所有foo替换成bar
Fn+右键
光标跳到当前行最后一个字符
Fn+右键、0
光标跳到当前行第一个字符
Ctrl+f、Ctrl+b
上下翻页
file file命令用于查看文件的类型,格式为“file 文件名”。
在Linux系统中,由于文本、目录、设备等所有这些一切都统称为文件,而我们又不能单凭后缀就知道具体的文件类型,这时就需要使用file命令来查看文件类型了。
1 2 3 4 5 [root@master01 ~]# file admin-openrc.sh admin-openrc.sh: ASCII text [root@master01 ~]# file /dev/sda /dev/sda: block special (8/0)
wc wc 命令用于统计指定文本的行数、字数、字节数,格式为“wc [参数] 文本”。
参数
作用
-l只显示行数
-w只显示单词数
-c只显示字节数
网络管理 ip ip命令 用来显示或操纵Linux主机的路由、网络设备、策略路由和隧道,是Linux下较新的功能强大的网络配置工具。
网卡配置
1 2 3 4 5 6 7 8 9 10 11 ip link ip link set eth0 up ip link set eth0 down ip link set eth0 promisc on ip link set eth0 promisc offi ip link set eth0 txqueuelen 1200 ip link set eth0 mtu 1400 ip a ip a a 192.168.0.1/24 dev eth0 ip a d 192.168.0.1/24 dev eth0
ip命令配置网卡信息,在网卡或机器重启后配置会丢失。要想配置永久生效,那就要修改网卡配置文件。如下:
1 2 3 4 5 6 7 8 9 [Linux]# vi /etc/sysconfig/network-scripts/ifcfg-eth0 DEVICE="eth0" BOOTPROTO="static" BROADCAST="192.168.0.255" HWADDR="00:16:36:1B:BB:74" IPADDR="192.168.0.100" NETMASK="255.255.255.0" ONBOOT="yes"
路由配置
1 2 3 4 5 6 7 8 ip r ip r add default via 192.168.1.254 ip r d default ip r a 192.168.4.0/24 via 192.168.0.254 dev eth0 ip r a default via 192.168.0.254 dev eth0 ip r d 192.168.4.0/24 ip r d 192.168.1.0/24 dev eth0
netstat 有时进程之间需要通信,需要开启一个socket,socket就是对外建立连接的一个窗口,然后借助TCP协议进行通信。但进行通信之前首先需要进程开启一个端口,这时就可以通过netstat命令查看开启的端口以及由哪个进程开启
1 2 3 4 5 6 7 8 9 10 11 12 13 14 netstat -a netstat -at netstat -au netstat -lu netstat -anp|grep 8081 | grep LISTEN|awk '{printf $7}' |cut -d/ -f1 -n或--numeric:直接使用ip地址,而不通过域名服务器; -l或--listening:显示监控中的服务器的Socket -p或--programs:添加“PID/进程名称”到netstat输出中;
ss ss 可以用来获取socket统计信息,它可以显示和netstat类似的内容。但ss的优势在于它能够显示更多更详细的有关TCP和连接状态的信息,而且比netstat更快速更高效。
1 2 3 4 5 6 ss -t -a ss -u -a ss -s ss -l ss -pl ss -lp | grep 3306
系统管理 firewalld-cmd firewalld是centos7的一大特性,最大的好处有两个:支持动态更新,不用重启服务;第二个就是加入了防火墙的“zone”概念。
firewalld自身并不具备防火墙的功能,而是和iptables一样需要通过内核的netfilter来实现,也就是说firewalld和 iptables一样,他们的作用都是用于维护规则,而真正使用规则干活的是内核的netfilter,只不过firewalld和iptables的结 构以及使用方法不一样罢了。
1 2 3 4 5 6 7 8 9 10 11 [root@master01 ~]# firewall-cmd --zone=public --list-ports 2121/tcp 3306/tcp 8081/tcp 30000/tcp 38060/tcp 40000/tcp 40001/tcp [root@master01 ~]# firewall-cmd --permanent --add-port=3307/tcp --zone=public success [root@master01 ~]# firewall-cmd --reload success [root@master01 ~]# firewall-cmd --zone=public --list-ports 2121/tcp 3306/tcp 3307/tcp 8081/tcp 30000/tcp 38060/tcp 40000/tcp 40001/tcp
firewalld中常见的zone(默认为public)以及相应的策略规则如下所示:
区域
默认规则策略
trusted
允许所有的数据包
home
拒绝流入的流量,除非与流出的流量相关;而如果流量与ssh、mdns、ipp-client、amba-client与dhcpv6-client服务相关,则允许流量
internal
等同于home区域
work
拒绝流入的流量,除非与流出的流量相关;而如果流量与ssh、ipp-client与dhcpv6-client服务相关,则允许流量
public
拒绝流入的流量,除非与流出的流量相关;而如果流量与ssh、dhcpv6-client服务相关,则允许流量
external
拒绝流入的流量,除非与流出的流量相关;而如果流量与ssh服务相关,则允许流量
dmz
拒绝流入的流量,除非与流出的流量相关;而如果流量与ssh服务相关,则允许流量
block
拒绝流入的流量,除非与流出的流量相关
drop
拒绝流入的流量,除非与流出的流量相关
ps ps命令 用于报告当前系统的进程状态。
参数
作用
-a
显示所有进程(包括其他用户的进程)
-u
用户以及其他详细信息
-x
显示没有控制终端的进程
1 2 3 4 5 6 ps -efww ps -auxf | sort -nr -k 4 | head -10 ps -auxf | sort -nr -k 3 | head -10
journalctl 检索 systemd 日志,是 CentOS 7 才有的工具
1 2 3 journalctl -u kubelet.service journalctl -u etcd.service -f -n 100
如果不知道服务名称,可以使用systemctl list-units --type=service命令来列出系统中的 systemd 服务。
watch watch命令 以周期性的方式执行给定的指令,指令输出以全屏方式显示
1 2 watch -d -n 60 "free -h"
rpm rpm命令 是RPM软件包的管理工具
1 2 3 4 5 6 7 8 rpm -qa rpm -ivh your-package.rpm rpm -ql nfs-utils-1.3.0-0.54.el7.x86_64
crontab crontab命令 被用来提交和管理用户的需要周期性执行的任务
用户可以使用 crontab 工具来定制自己的计划任务。所有用户定义的crontab文件都被保存在/var/spool/cron目录中。其文件名与用户名一致。
crontab文件的含义:用户所建立的crontab文件中,每一行都代表一项任务,每行的每个字段代表一项设置,它的格式共分为六个字段,前五段是时间设定段,第六段是要执行的命令段,格式如下:
1 minute hour day month week command 顺序:分 时 日 月 周
1 2 3 4 5 6 7 8 9 10 11 12 [root@master01 ~]# cat /var/spool/cron/root 0 * * * * sh /opt/free.sh 0 * * * * sh /opt/diskcheck.sh [root@master01 ~]# crontab -l 0 * * * * sh /opt/free.sh 0 * * * * sh /opt/diskcheck.sh
进阶操作 nohup nohup命令 可以将程序以忽略挂起信号的方式运行起来,被运行的程序的输出信息将不会显示到终端。
1 2 nohup sh install.sh > output.log 2>&1 &
script script 用于在终端会话中,记录用户的所有操作和命令的输出信息。
使用命令exit或者快捷键Ctrl + D停止记录。
chattr chattr命令 用来改变文件属性。这些属性共有以下8种模式:
1 2 3 4 5 6 7 8 9 10 11 12 a:让文件或目录仅供附加用途; b:不更新文件或目录的最后存取时间; c:将文件或目录压缩后存放; d:将文件或目录排除在倾倒操作之外; i:不得任意更动文件或目录; s:保密性删除文件或目录; S:即时更新文件或目录; u:预防意外删除。 +<属性>:开启文件或目录的该项属性; -<属性>:关闭文件或目录的该项属性; =<属性>:指定文件或目录的该项属性。
用chattr命令防止系统中某个关键文件被修改:
然后试一下rm、mv、rename等命令操作于该文件,都是得到Operation not permitted的结果。
让某个文件只能往里面追加内容,不能删除,一些日志文件适用于这种操作:
1 chattr +a /var/log/ansible.log